Loading LOTS of data into DynamoDB
In my day job, I do a lot of performance testing. A project I’m working on is being implemented using serverless technology – Lambdas, API Gateway, Step Functions etc… and also DynamoDB!
One of the new components was a Step Function that would load a certain set of items from DynamoDB (millions), do some processing, and then write a whole new load of items to Dynamo (or as it ended up being, S3, but that’s a story for another time)
To test this component, we needed a way to populate DynamoDB with the millions of items necessary, preferably quickly and cheaply. This is the journey to that goal.
Things of note that will be important later…
- We are using the ‘On Demand’ capacity mode for DynamoDB.
- DynamoDB does not provide functionality to empty a table. The only way to this is to either:
- Scan all items and send delete requests for each one
- Delete and recreate a table <- this is what we were doing
Where to start…
In other similar products we use MySQL databases, and I created scripts that would generate the data required based on supplied parameters, and then batch insert these into MySQL. It was reasonably quick depending on the size of the database and how much data was being input (maybe ~20 minutes for 20,000,000 rows), but because you can truncate a table in MySQL very quickly, or even delete data fairly quickly, I would actually only do the big data load once at the start of testing, and then truncate or delete out the data no-longer needed in-between tests (taking a few seconds to do each time).
I started off trying to do something similar. DynamoDB provides a BatchWriteItem operation which can write 25 items per request. I created a script that would generate the data and send it to Dynamo using BatchWriteItem. However when I tried to run this script, it took hours just to insert small amounts of data (100,000s). It was clear this strategy was not going to work, synchronously making HTTP requests is way too slow.
Introducing Step Functions…
A new design was needed, and the choice was made to use Step Functions and Go Lambdas, the same as the component the data was going to be used to test. The new data creator tool was developed, deployed and tested. And it worked! It created millions of items of data in minutes! Success.
During the development though a few things of note came up:
- Step functions have an input and results data size limit of 32,768 characters. This is actually quite easy to exceed and is quite a lot less than the individual Lambda maximum payload size (256KB). Quite an annoying limit and trip us up quite quickly needing a re-think of the data structure used.
- The Step Function is using Map states which take an array of data and pass it to Lambdas in parallel. We expected this to spin up as many Lambdas as there were array items, however it did not seem to do this, instead processing around 40-90 items at a time. This meant it was slower than it could have been.
The Strange Behaviour Of BatchWriteItem…
After we had been happily using this Step Function for a few weeks to create data, we suddenly made a discovery. There wasn’t as much data in Dynamo as there should have been. This was very confusing.
The code checked for errors, so if a BatchWriteItem had failed we would have caught it, and the Lambdas were reporting no errors. How was this possible?
As it turned out, if BatchWriteItem fails to write any items to Dynamo, it will actually return an OK response with those failed items listed in the UnprocessedItems parameter. The docs do mention this but at the point the code was implemented it wasn’t appreciated what that actually meant, but assumed that an error would return… an error! This had meant all this time, we’d actually only been writing a fraction of the data to Dynamo, and our super fast speeds we’d been so happy about were totally untrue!
The code was rewritten to check for UnproccessedItems and retry them with a backoff. This meant all items were being written to the database, but our numbers for how long it took were obviously a lot longer, more like 10 minutes than 2 for an equivalent amount of data.
Dynamo On Demand Scaling…
As mentioned earlier, we use Dynamo’s On Demand capacity mode. This makes the following claims:
For tables using on-demand mode, DynamoDB instantly accommodates customers’ workloads as they ramp up or down to any previously observed traffic level. If the level of traffic hits a new peak, DynamoDB adapts rapidly to accommodate the workload.
https://aws.amazon.com/blogs/aws/amazon-dynamodb-on-demand-no-capacity-planning-and-pay-per-request-pricing/
On Demand was chosen for both our test and productions sites. For test because obviously their use is very low, and it saves us considerable money to only pay for what we use. For prod, because our traffic pattern is very spiky, and we were hoping to be able to rely on the ‘rapid’ workload accommodation, and again save money during the majority of the time when load is low.
We were also hoping this would allow for rapid data insertion, scaling up to handle the very large and short lived spike as the Step Function was running.
Unfortunately as part of discovering that we were failing to write some of the items, we discovered that the reason we were failing was because we were being throttled. A lot.
Write Capacity:
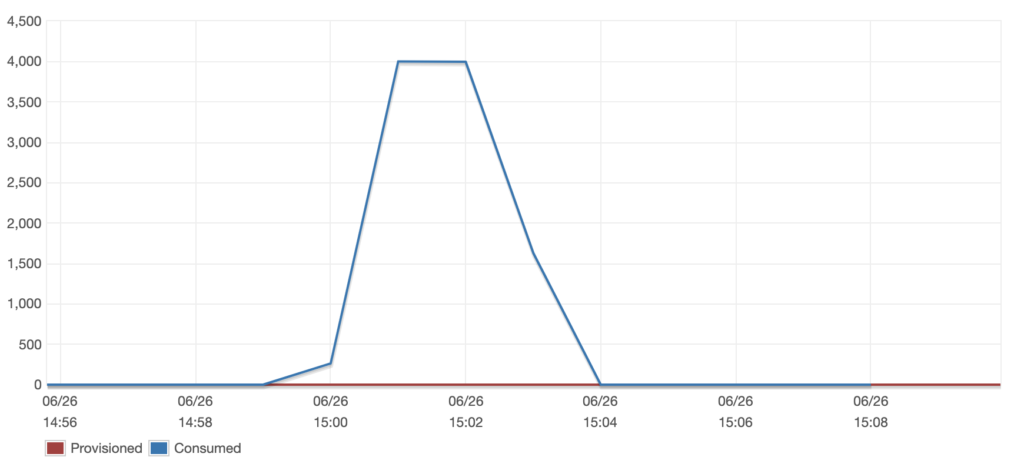
Throttled Write Events:
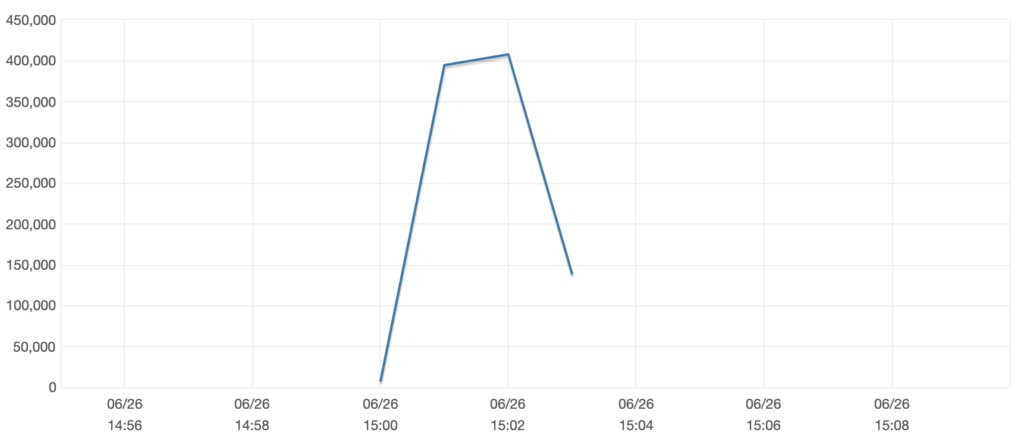
We didn’t understand why we weren’t getting above 4000 writes/s. Dynamo docs suggested it should rapidly scale to meet demand, but it didn’t seem to be.
Lots of googling around and this very useful blog post was found: https://theburningmonk.com/2019/03/understanding-the-scaling-behaviour-of-dynamodb-ondemand-tables/
Newly created tables can only scale up to 4000 writes/s, and they will only increase their capacity once the consumed capacity exceeds that. Additionally the time it takes to scale is fairly large, around 10 minutes from the experiments performed in that blog post. This was not the ‘rapid’ accommodation we had hoped for, and had implications for both our test and production sites.
As suggested in that blog post, we are planning to provision our table with 40,000 writes/s on creation, then switch back to On Demand afterwards. Will update with results!
Update!
Gave it a whirl, and while I could in principle get it to work as intended, we didn’t end up actually using this method for a few reasons:
- It takes a very long time to switch from Provisioned to On Demand mode (like, an hour). This means that while it speeds up the actual data insertion, it takes longer overall when you account for switching back to On Demand ready for the test to run.
- We weren’t planning to do this for our production environment, which means tests run on the test environment where we are artificially ‘pre-warming’ the database will not be applicable to the production environment.
- You need to be certain the database has switched back to On Demand mode after provisioning it in Provisioned mode else you will rack up a very large bill, very quickly. I was uncomfortable with a process that could end up costing a lot of money if a mistake was made.